![[BIENGUAL] SEO 기반 작업과 배운 점](/images/thumbnail/seo.webp)
BIENGUAL 프로젝트를 처음 시작했을 때, SEO(검색 엔진 최적화)에 대해 구체적인 이해 없이 단순히 "검색에 잘 나오게 해야겠다"는 생각뿐이었습니다. 초기에는 구글 검색에 등록조차 안 되어 있었고, 콘텐츠를 공유할 때도 제목과 설명이 누락된 밋밋한 링크가 표시되는 상황이었습니다.
이 글에서는 BIENGUAL에서 진행한 SEO 기반 작업과 그 과정에서 배운 점들을 공유하겠습니다.
SEO 작업을 시작한 이유
BIENGUAL은 유튜브와 CNN 기사의 썸네일을 활용해 학습 콘텐츠를 제공하는 플랫폼입니다. 사용자가 원하는 콘텐츠를 빠르게 찾고 접근할 수 있으려면 검색 노출이 필수적이었습니다. 하지만 초기에는 SEO 작업에 필요한 기본적인 설정조차 되어 있지 않았습니다:
-
사이트맵 부재
검색 엔진이 크롤링할 페이지를 알 수 있는 정보가 없어 우리의 콘텐츠가 검색 결과에 제대로 반영되지 않았습니다. -
메타데이터 부재
소셜 미디어나 검색 결과에서 콘텐츠를 공유할 때, 제목과 이미지 없이 누락된 정보가 표시되었습니다. -
robots.txt 미설정
검색 엔진이 크롤링하면 안 되는 관리자 페이지나 개인 페이지까지 모두 공개되고 있었습니다.
이 상태로는 사용자 유입을 기대할 수 없었기 때문에, SEO 기반 작업이 필수라는 결론에 도달했습니다.
진행한 작업
1. 메타데이터 설정
Next.js의 generateMetadata 함수를 활용해 각 콘텐츠에 맞는 메타 태그를 설정했습니다. 메타 태그는 검색 결과에서 표시되는 제목과 설명뿐만 아니라, 소셜 미디어에서 콘텐츠를 공유할 때 중요한 역할을 합니다.
export async function generateMetadata({
params,
}: {
params: { id: string };
}): Promise<Metadata> {
const contentId = Number(params.id);
const res = await fetchContentDetail(contentId);
const contentData = res.data;
return {
title: contentData.title || 'Biengual',
openGraph: {
title: contentData.title,
images: contentData.thumbnailUrl ? [contentData.thumbnailUrl] : [],
},
};
}
이 작업을 통해 공유 링크의 제목과 이미지를 설정할 수 있었으며, 검색 엔진에서도 콘텐츠를 좀 더 풍부하게 표현할 수 있었습니다.
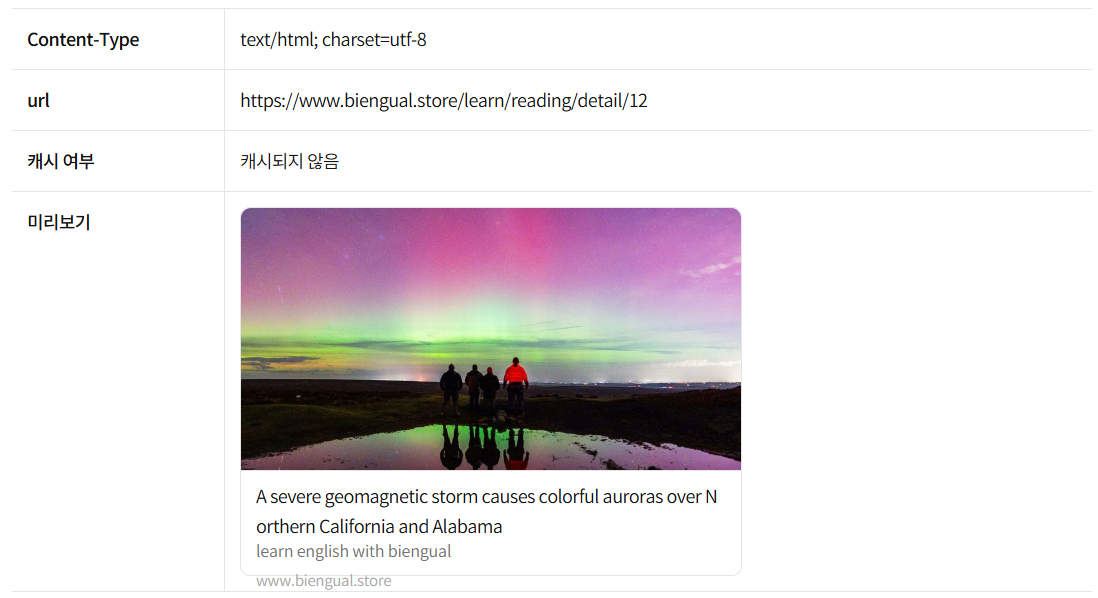
2. 사이트맵 생성
구글과 같은 검색 엔진이 우리의 콘텐츠를 효율적으로 크롤링할 수 있도록 동적 사이트맵을 설정했습니다. BIENGUAL의 콘텐츠는 지속적으로 추가되기 때문에, 동적 데이터를 기반으로 사이트맵을 생성해야 했습니다:
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const contents = await fetchPaginatedListeningPreview(
0,
50000,
'createdAt',
'DESC',
);
return contents.data.contents.map((content) => ({
url: `https://www.biengual.store/learn/listening/detail/${content.contentId}`,
lastModified: new Date(),
}));
}
구글 서치 콘솔에 사이트맵을 등록해 검색 엔진이 모든 콘텐츠를 제대로 크롤링할 수 있음을 확인했습니다.
3. robots.txt 설정
검색 엔진이 크롤링하면 안 되는 페이지를 제한하기 위해 robots.txt 파일을 설정했습니다. 개인 정보가 포함된 페이지나 관리자 페이지가 검색 결과에 노출되는 일을 방지했습니다:
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: '*',
allow: '/',
disallow: ['/mypage', '/admin', '/dashboard'],
},
sitemap: 'https://www.biengual.store/sitemap.xml',
};
}
SEO를 통해 배운 점
SEO 기반 작업을 진행하며 단순히 "검색에 잘 나오자"는 것 이상의 많은 것을 배울 수 있었습니다.
1. 기반 작업만으로는 충분하지 않다
사이트맵, 메타데이터, robots.txt 설정은 필수적인 첫 단계였지만, 이것만으로 검색 노출을 획기적으로 개선할 수는 없었습니다. 더 많은 검색 유입을 위해서는 어떤 키워드로 검색될지를 고민하고, 경쟁자를 분석하며, 검색 엔진이 우리의 콘텐츠를 더 잘 이해할 수 있도록 콘텐츠를 최적화해야 합니다.
2. 데이터 해석 능력의 중요성
구글 서치 콘솔의 데이터를 분석하며 CTR(Click-Through Rate)와 Average Position의 의미를 배웠습니다:
- CTR: 노출 대비 클릭 비율로, 제목과 설명이 사용자에게 얼마나 매력적으로 보였는지를 나타냅니다.
- Average Position: 검색 결과에서 콘텐츠가 평균적으로 노출된 위치를 보여줍니다.
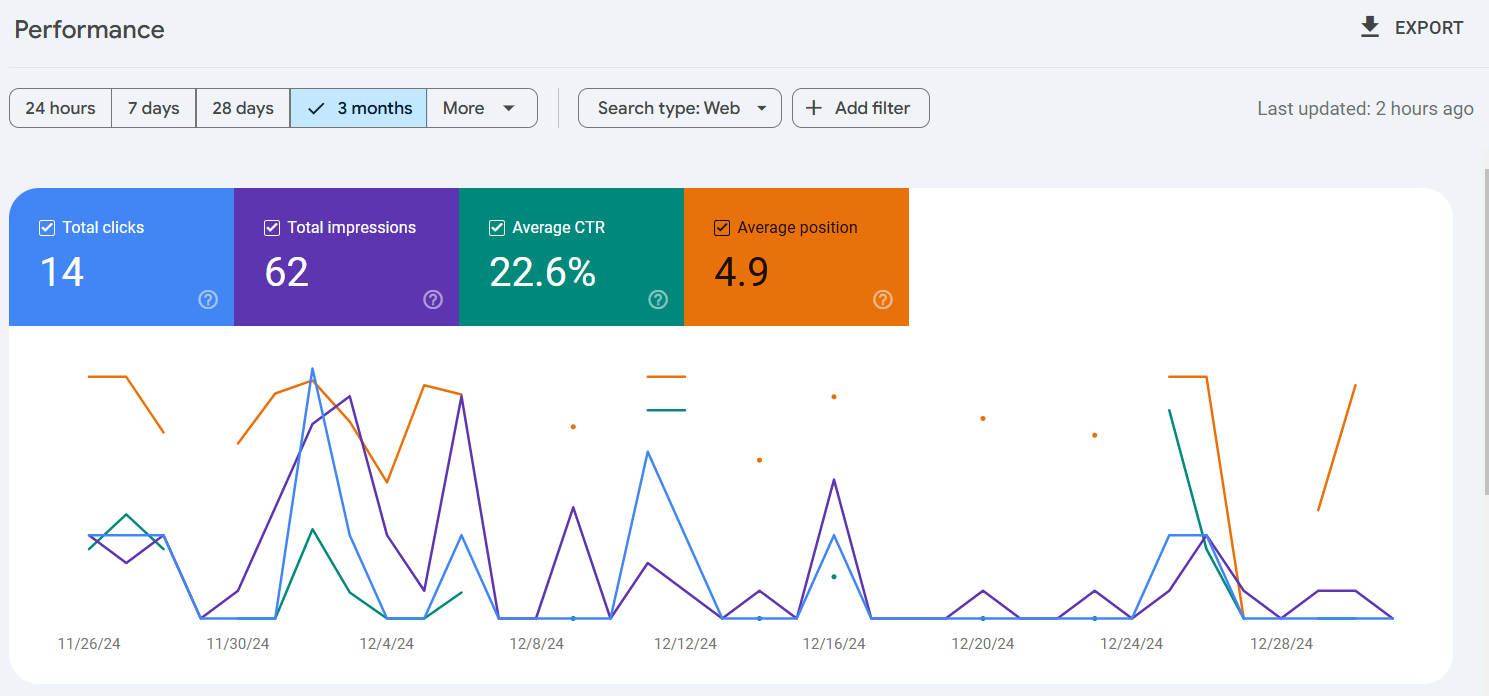
초기 데이터를 보면 CTR이 22.6%, Average Position이 4.9라는 수치를 기록했지만, 이는 제한적인 노출량과 클릭 수로 인해 실제 유의미한 해석을 하기는 어려웠습니다. 이 과정을 통해 단순한 숫자에 현혹되지 않고, 데이터를 맥락 속에서 이해해야 한다는 점을 배웠습니다.
3. 검색 엔진 최적화는 장기적인 작업이다
SEO는 단기적으로 큰 변화를 기대하기 어렵습니다. 하지만 지속적인 최적화와 개선 작업을 통해 점진적으로 더 많은 사용자를 유입할 수 있습니다. 특히 대기업이 특정 키워드를 '점유'한다는 것이 어떤 의미인지 조사하며, 키워드 선정과 콘텐츠 작성의 중요성을 실감했습니다.
결론
BIENGUAL 프로젝트에서 SEO 기반 작업은 이제 막 첫걸음을 뗀 상태입니다. 사이트맵과 메타데이터, robots.txt 설정은 필수적인 기반 작업이었지만, 이를 넘어서 검색 엔진에서의 노출과 유입을 더욱 강화하려면 더 깊이 있는 고민과 작업이 필요합니다.
이번 작업을 통해 SEO가 단순히 기술적인 작업에 그치지 않고, 사용자가 콘텐츠를 어떻게 검색하고 접근하는지를 고민하는 작업이라는 점을 배웠습니다. 앞으로는 키워드 전략과 콘텐츠 최적화 등 더욱 체계적인 SEO 작업을 이어갈 계획입니다.